Summry
본 문서에서는 대용량 트래픽 처리 방식에 대해 간단히 정리한다.
send me email if you have any questions.
로드밸런싱(Load Balancing)
정의
로드밸런싱(Load Balancing)이란 트래픽이 많을 때 여러 대의 서버가 분산처리하여 서버의 로드율을 증가, 부하량, 속도저하등 고려하여 분산처리하여 해결해주는 서비스이다.
로드밸런싱(Load Balancing)을 해주는 소프트웨어 혹은 하드웨어 장비를 로드밸런서(Load Balancer)라고 한다.
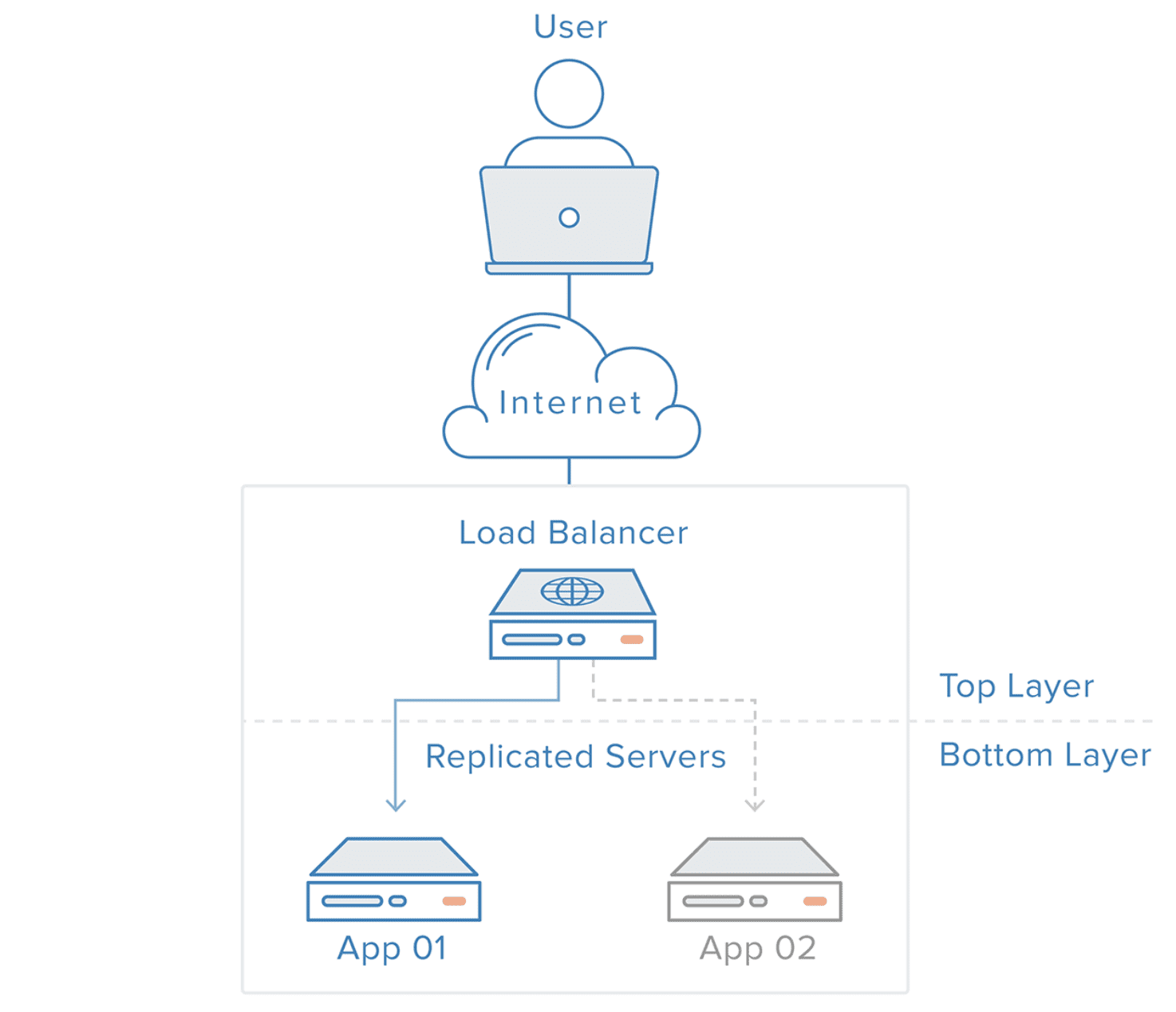
동작 방식
- 네트워크 상단에 L4 스위치 가상서버가 존재하여 서버로 들어오는 패킷을 리얼 서버로 균일하게 트래픽을 분산시킨다.
- 서버에 장애가 발생하면 이를 감지하여 정상적으로 작동하는 서버로 트래픽을 분산시킨다.
로드밸런싱은 하나의 서비스를 하나 이상의 노드가 처리하는 식으로 작동한다.
로드밸런싱을 위한 서비스 요청 처리 알고리즘은 다양하다.
랜덤, 라운드 로빈, CPU나 메모리 사용률 등과 같은 특정 범주에 따라 노드를 선택하는 등의 방법이 있다.
오픈소스 로드밸런서 중 많이 사용되고 있는 것은 HAProxy이다.
로드밸런싱 종류와 방법
L4 Load Balancing
L4 Load Balancer는 L4계층에서 동작하는 Load Balancer이므로 네트워크 계층이나 트랜스포트 계층의 정보를 바탕으로 로드를 분산한다. 즉, IP주소나 포트번호, MAC주소, 전송 프로토콜 등에 따라 트래픽을 나누고 분산처리 하는 것이 가능하다. 이런 이유로 L4 Load Balancer를 CLB(Connection Load Balancer) 혹은 SLB(Session Load Balancer)라고 부르기도 한다.
L4 Load Balancing 방법
- 라운드 로빈(Round Robin)기반 : 세션을 각 서버에 순차적으로 맺어주는 방식이다.
- 단순히 순서에 따라 세션을 할당하기 때문에 경웨 따라 경로별로 같은 처리량이 보장되지 않는다.
- 가중치 및 비율 할당 방식 : 서버마다 비율을 설저앻두고 해당 비율 만큼 세션을 맺어주는 방식이다.
- 특정 서버의 성능이 월등히 뛰어나다면 해당 서버로 세션을 많이 맺어주도록 가중치를 설정하고 나머지 로우급의 서버들은 적은 세션이 맺어질 수 있도록 가중치를 설정한다.
- 최소 연결(Least Connection)기반 : 가장 적은 세션을 가진 서버로 트래픽을 보내는 방식이다.
- 가장 많이 사용되는 방식
- 응답 시간(Response Time)기반 : 가장 빠른 응답 시간을 보내는 서버로 트래픽을 우선 보내주는 방식이다.
- 각 서버들의 가용 가능한 리소스와 성능, 처리중인 데이터 양이 다를 경우 적합한 방식이다.
- 해시(Hash)기반 : 특정 클라이언트는 특정 서버로만 할당시키는 방식이다.
- 특정 IP주소 또는 Port의 클라이언트들은 특정 서버로만 세션이 맺어지도록 한다. 경로가 보장되며 접속자 수가 많을수록 분산 및 효율이 뛰어나다.
- 대역폭(Bandwidth)기반 : 서버들과의 대역폭을 고려하여 트래픽을 분산시키는 방법이다.
L7 Load Balancing
L7 Load Balancer는 위와 같은 L4 Load Balancer의 기능을 포함하는 것 뿐만 아니라 OSI 7계층의 프로토콜을 바탕으로도 분산 처리가 가능하다.
L7 Load Balancing 방법
- URL Switching : 특정 하위 URL들은 특정 서버로 처리하는 방식이다.
- 예를 들어 ‘…/limjunho/test1’ 또는 ‘…/limjunho/test2’와 같은 특정 URL을 가진 주소들은 서버가 아닌 별도의 스토리지에 있는 객체 데이터로 바로 연결되도록 구성할 수 있다.
- Context Switching : 클라이언트가 요청한 특정 리소스에 대해 특정 서버 등으로 연결을 해줄 수 있다.
- 예를 들어 이미지 파일에 대해서는 확장자를 참조하여 별도로 구성된 이미지 파일이 있는 서버/스토리지로 직접 연결해줄 수 있다.
- 쿠키 지속성(Persistence with Cookies) : 쿠키 정보를 바탕으로 클라이언트가 연결 했었던 동일한 서버에 계속 할당해주는 방식이다.
- 특히 사설 네트워크에 있던 클라리언트의 IP주소가 공인 IP주소로 치환되어 전송(X-Forwarded-For Header에 클라이언트 IP주소를 별도 기록)하는 방식을 지원한다.
장점
- 로드밸런싱을 이용하면 한 서버가 다운되더라도 이중화시킨 다른 서버에서 서비스를 지속하여, 사용자들이 문제를 인지하지 못하게 할 수 있다.
- 단지 노드를 추가하는 것만으로 서비스가 확장성을 가질 수 있다.
단점
- 로드밸런서를 사용할 때 어려운 문제 중 하나는 세션 데이터를 관리하는 것이다.
- 클라이언트의 연결 정보를 저장하는 세션이 로드밸런싱을 통해 하나의 서버 장비에 저장이 되는 경우, 추후 다른 서버로 접속하게 되면, 해당 클라이언트의 세션이 유지되지 않는다는 것이다. 즉, 서버에 액세스 할 때마다 다른 세션을 사용한다면 특정 사용자의 정보를 일관성있게 유지할 수 없게 된다.
- 이러한 문제를 해결하기 위해 세션을 고정(session sticky)한다. 하지만 고정된 세션의 노드에 장애가 발생하면 고정한 의미가 없어진다.
L4/L7 Load Balancer의 성능 지표
- 초당 연결 수(Connections per second)
- 최대 처리 가능한 초당 TCP 세션의 개수를 의미
- 동시 연결 수(Concurrent connections)
- 동시에 최대로 세션을 유지할 수 있는 개수를 의미
- 처리용량(Throughput)
- UDP Protocol에 대한 Load Balancing 성능 지표이며 단위는 bps(bit per second) 또는 pps(packet per second)를 사용
클러스터링(Clustering)
Clustering이란 여러 대의 컴퓨터를 똑같은 구성의 서버군을 병렬로 연결한 시스템으로 마치 하나의 컴퓨터처럼 사용하는 것을 말한다.
- Clustering 환경에서는 특정 장비에 문제가 생기거나 애플리케이션에 문제가 생기더라도, 전체적인 서비스에는 영향을 주지 않게 제어할 수 있다.
- Clustering은 Virtual IP(가상 IP) 기반으로 구현되는데, 서비스를 제공하는 실제 장비는 Physical IP를 가지고, 데이터의 처리는 Virtual IP를 통해 처리한다. 이렇게 내부의 시스템은 철저하게 가려 추상화하는 것이 원칙이다.
- 로드밸런서에 의해 각 Clustering된 서버에 의해 서비스가 진행이 된다.
정리
Load Balancing은 L4 or L7이 여러대의 서버에 패킷을 부하분산시켜주는 것이고 Clustering은 여러대의 서버를 하나의 서버로 만들어 주는 것이다.
- Load Balancing - 여러대의 서버에 패킷을 분산
- Clustering - 서비스를 제공하는 여러개의 서버를 하나로 묶어 성능을 높여 많은양의 패킷을 처리하는 것
Reference
대용량 트래픽 처리 - 정지롤
네이버 메인 페이지의 트래픽 처리 - NAVER D2 로드 밸런싱과 클러스터링 - goodGid
[이해하기] 네트워크의 부하분산, 로드밸런싱(Load Balancing) 그리고 로드밸런서 (Load Balancer) - STEVEN J. LEE